
聚类1
聚类是什么?(kmeans)
- 不同于前面的监督学习(有类别作为参考),聚类是无监督学习,算法可以自己将相似的样本分为一类。
- 分类可以对不同类别进行针对性的操作。
如何做到?
- 找到k个聚类中心。
- 将点按照距离分为k类。
- 欧氏距离:根号下…,用的最多。
- 余弦距离
- 马氏距离
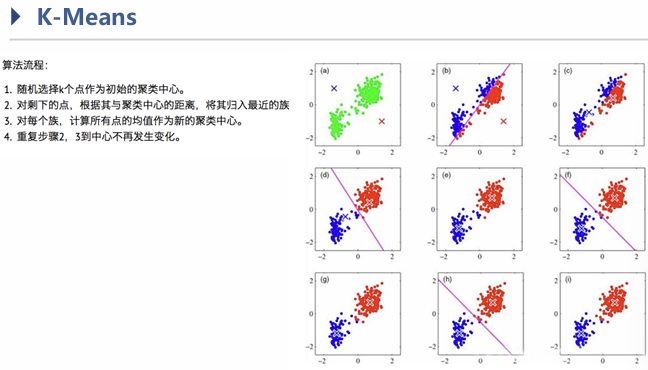
- 策略:计算所有点到相应聚类中心的距离,求和,取最小。一般可以用迭代的方式。

策略 - 具体方法:
不断寻找新的聚类中心,但有缺点:聚类中心到底需要几个?初始化,局部最优问题?具体

解决细节问题
- K值的确定:
肘方法(elbow方法)
k选择肘图转折点对应的k值即可。 - 局部最优问题:
K-Means++算法。(sklearn里面大多用这个算法)kmeans++算法







