逻辑回归2
为什么要设立分类评价指标?
- 确定模型是否能用。
- 避免特殊情况下的唯准确率论,如样本不平衡,1个A,99个B的情况。
评估指标
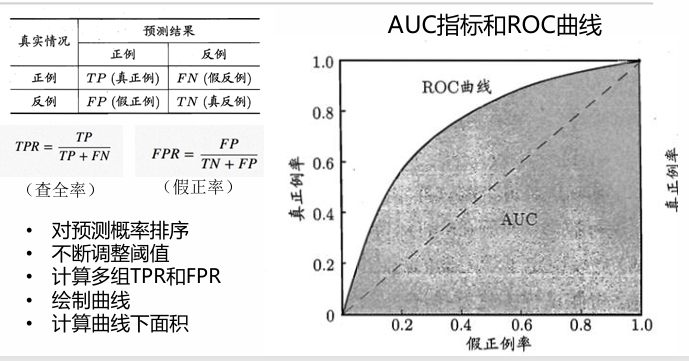
- 混淆矩阵
如混淆矩阵所示,所以求出查准率和查全率。
根据这两个指标即可解决样本不均衡导致的单准确率无法判断模型优劣的问题。
往往,我们要求查准率和查全率都要高,但实际上一方高了另一方会偏低。
查准率偏向于使用训练集测试结果,查全率偏向于实际使用上的具体结果。
评估指标 - 什么时候用什么?
查准率:如人脸识别,只关心预测对不对。
查全率:确认诈骗信息,挖掘诈骗邮件,挖掘少数的样本。 - F1指标
F1指标表示了同时考虑两种情况,越大越好。F1指标 - AUC指标、ROC曲线,面积越大模型效果越好。
AUC指标和ROC曲线 - 多分类问题怎么办?
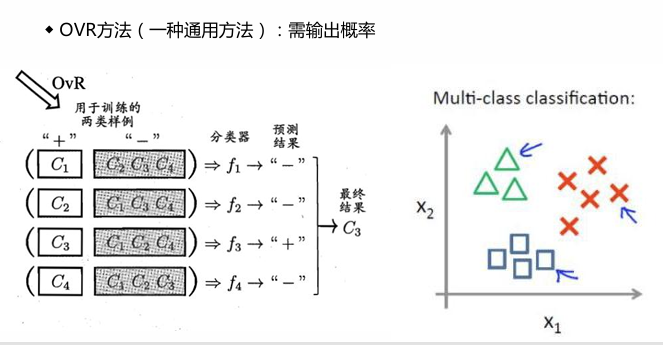
OVR策略(one vs rest)
OVR输出概率,看看输入的东西属于什么的概率最大,就当做哪一类。
详细来说,就是将某一类样本当做一类,其他当做其他类,再分别对所有类别做如此操作,得出P1 P2 P3,最后哪个概率大就是那个。
实际上,在python里面都会简单化。多分类 - 多分类评估指标
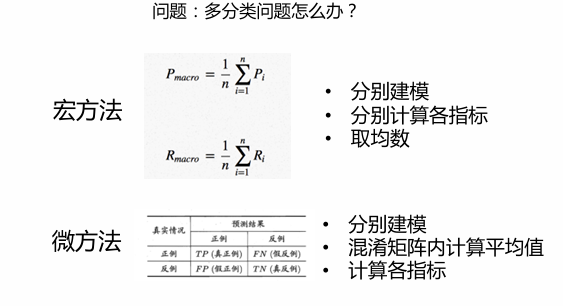
宏方法:分别建模、计算指标、取平均数
微方法:建模、矩阵内计算平均值、计算各指标多分类评估