
机器学习简介
机器学习基本概念
一、机器学习是什么?
- 机器学习:研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的组织结构使之不断改善自身的性能。
比如认识“猫”,见得多了就知道是什么了
- 理论:统计学、信息论、决策论、最优化、矩阵论、数据结构、分布式理论等。工具:python包:numpy、pandas、sklearn、matplotlib等、spark(分布式,多台机子计算一个问题)、mlib、hive等。
二、解决的问题
- 数据挖掘,记录一个页面中用户的操作,判断是否为潜在客户。
- 计算机视觉,识别事物,图像处理。
- 自然语言处理,给一句中文,判断表达的情感,根据评论找出产品缺陷。
- 语音处理,小爱同学,语音导航。
- 推荐系统,电商平台推荐商品。
以数据挖掘为例:
医院中:病人数据→预测患病可能。
电商网站:用户浏览记录→推荐商品。
餐馆:往日点餐→未来食材准备。
机器学习举例 难度越高,需要的f越复杂

三、思路与基本步骤
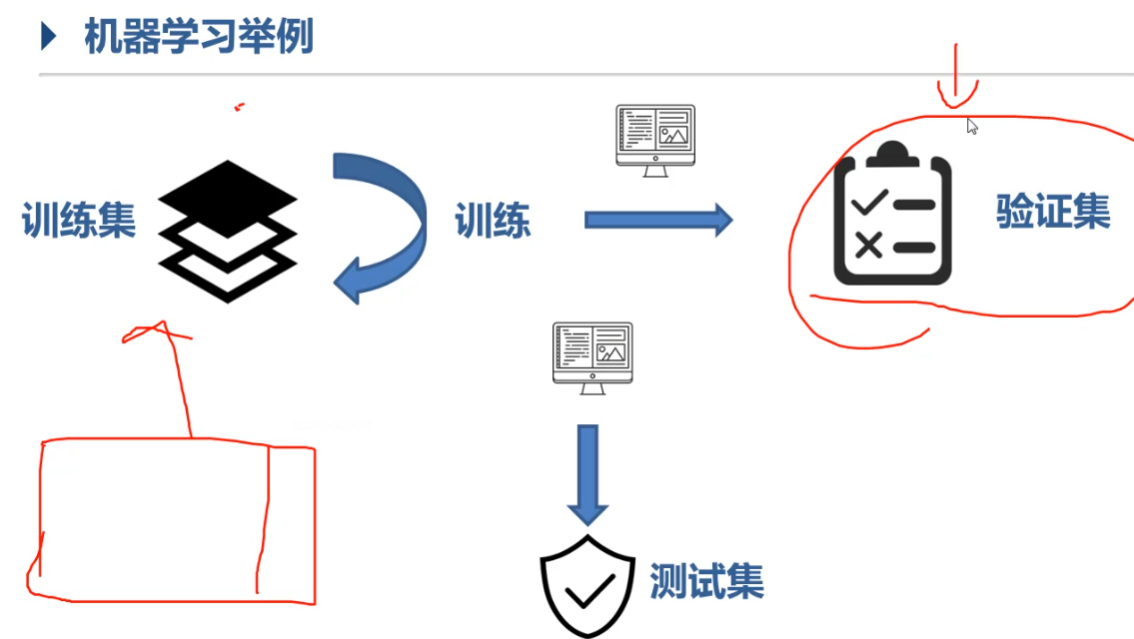
机器学习示意
机器学习示意图 通过训练集训练f,用验证集进行检验,最后用测试集进行测试。
基本步骤
2.1 分析问题→获取数据→清洗数据(数据探索)→特征工程(筛选那些数据对训练有帮助,根据已有特征构造想新特征等)→构建模型→模型调参→模型上线分析问题
3.1 将数据结构化,二维表结构,行列式,包含feature特征列(属性)、label标签列、sample样本列。有feature、label为监督学习,只通过feature来学习模型是无监督学习。
无监督学习,比如通过数据区分玩家类型(频率高、金额大和频率低、金额小),以类聚,发现数据本身的特点。
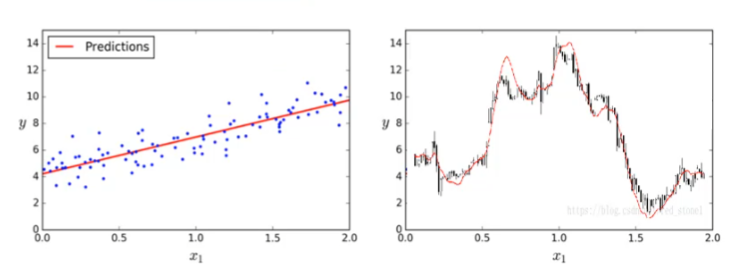
3.2 监督学习问题一:回归问题
label是连续值,线性回归是最简单的机器学习。回归问题 3.3 监督学习问题二:
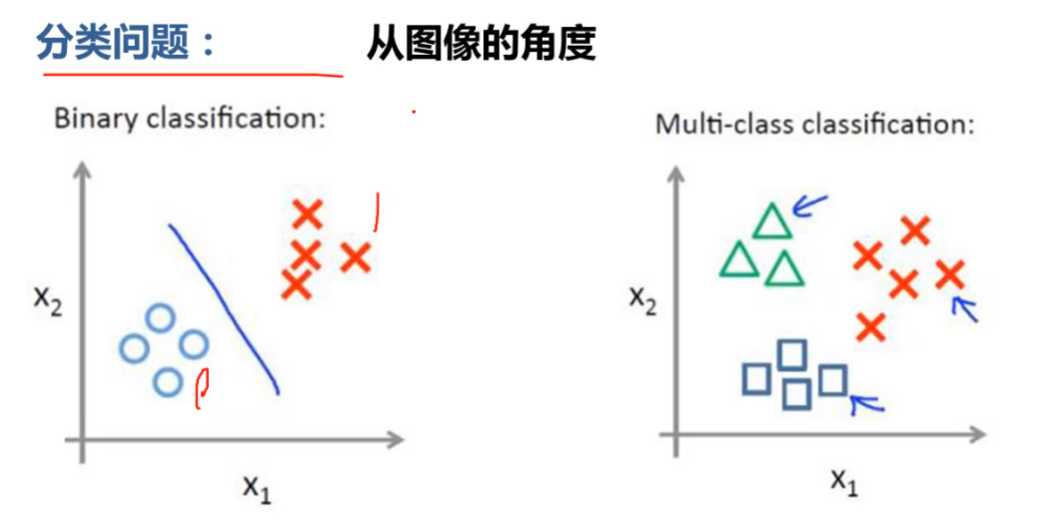
分类问题3.3.1 二分类问题,判断yes or no. 3.3.2 多分类问题,判断图片中的数字是几。 3.3.3 多标签的二分类、多分类。 3.3.4 从图像角度从图像角度 3.4 无监督学习:
3.4.1 数据没有标签怎么办?`聚类`。可能会有一些离群点,可以检测出来。 3.4.2 `降维问题`将1000组数据生成500组新的数据,1000维降到500维但仍然保持完整的信息,可以提高计算效率降维 3.4.3 更多的时候,非监督学习用于数据预处理阶段,让建模过程更流畅。

四、对应的岗位
BI分析师(做图表等,做一些决断)、ETL工程师(清洗数据)、数据挖掘工程师、数据分析师、AI算法工程师(优化算法,加速)








